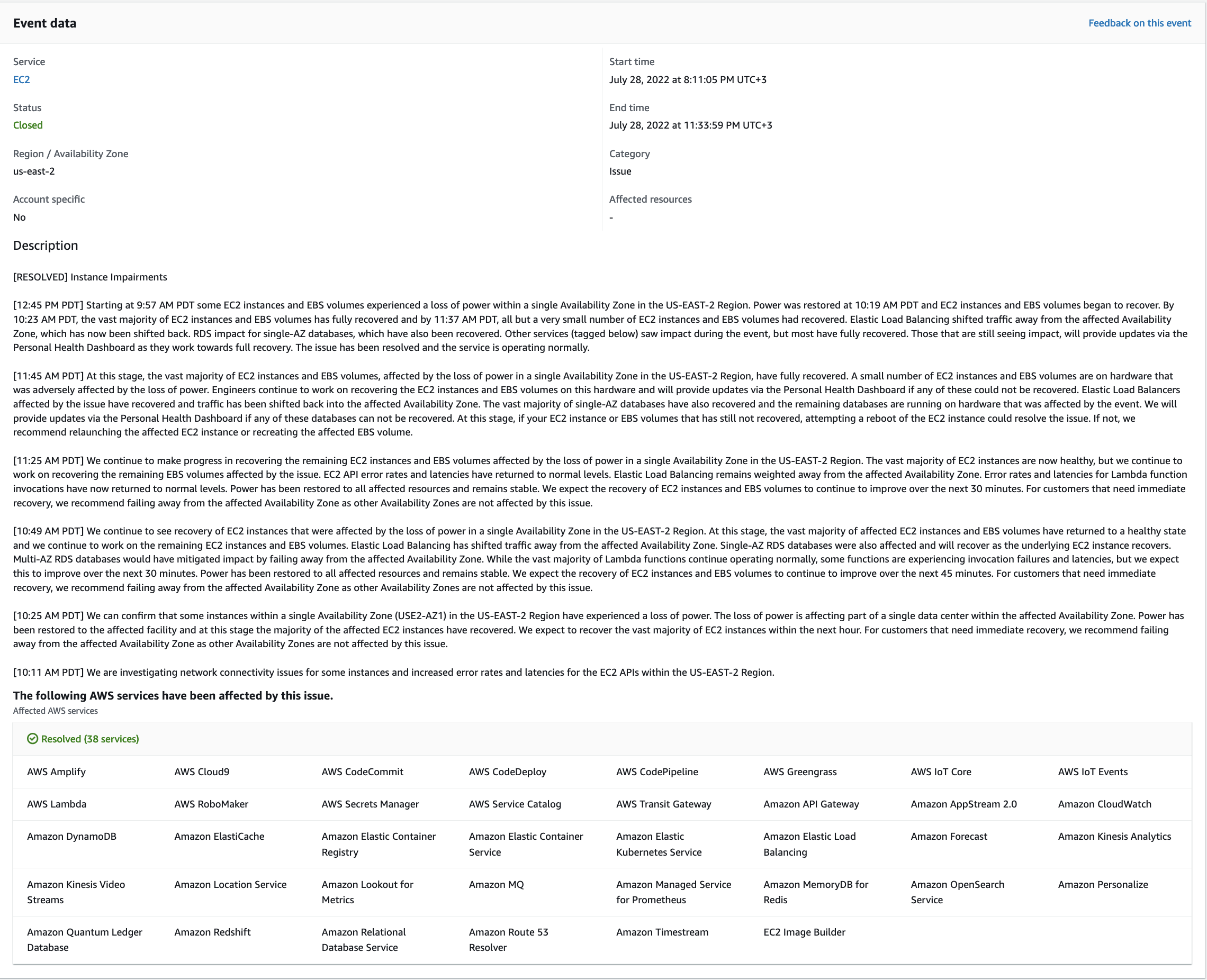
Coralogix Outage on July 28, 2022
Overview
Yesterday, July 28, 2022, Coralogix experienced an outage that affected traffic in 1 of our clusters running on AWS Ohio (us-east-2). This cluster handles a significant proportion of our customer-based traffic.
Root Cause
The root cause of this was the failure of 38 AWS services in the Ohio region starting at 10:00 AM PDT, caused by a power loss in an AWS data center.
Remediation
By 10:28 PDT, our cluster was back online. By 10:37 PDT we were processing the backlog of data from our customers, and we were waiting for AWS to recover the remaining services. The AWS incident was resolved by the Amazon team at 14:54 PDT and all services were recovered shortly after.
Impact
Coralogix is built to withstand AZ failures, but the scope and scale of this AWS outage caused a number of parallel failures to occur, which impacted our ability to deliver our service.
Timeline
10:06 PDT: On-call engineer was triggered with a high volume of alerts indicating issues on the Ohio cluster. This is when the incident was first detected.
10:11 PDT: Escalation to relevant stakeholders within Coralogix began.
10:21 PDT: Internal Coralogix incident declared.
10:24 PDT: Status page opened to inform all customers of the impact they may experience.
10:31 PDT: Traffic redirected to prevent data loss.
10:37 PDT: System functionality restored, but customers were still experiencing delays in data, alerting, live-tail and archiving. Thanks to earlier actions, all data is collected and stored.
10:37 PDT: System is carefully monitored to ensure quality of service.
01:54 PDT: Incident closed
Remediation and follow-up steps
We have already identified several areas of improvement and will continue our investigations to uncover any other gaps that could cause a recurrence. Here is what we are working on immediately:
Process
Our triage process for issues depends on the severity of issues declared by AWS. In this instance, AWS declared this issue as “Informational”, and indicated that only a small number of EC2 instances were impacted in the us-east-2 region, which delayed our response.
In future, we need to update our triage process and automation to rely on information from multiple sources, to ensure that we’re getting an accurate picture of the situation, first hand.
Architecture
This outage revealed some weaknesses in our disaster recovery processes, which are designed to handle AZ and region failure. Our primary goal is to prevent customer data loss, so that our recovery is always a complete one.
We intend to redesign parts of our disaster recovery mechanisms, at an architectural level, to completely support region failure without an impact to customer data.
Automation
In addition to the architectural changes we plan, we have identified changes we could make to our automation suite to completely mitigate the impact from this outage.
Primarily, we will be concentrating on automation improvements that relate to complete region failure and improved MTTA/MTTR during the incident.
Conclusion
While the root cause lay outside of our system, Coralogix has work to do to ensure we are completely resilient to these kinds of incidents in the future. This time, we’ve fallen short of our customer’s expectations. For that, we sincerely apologize.
We have already begun the changes outlined above, to ensure that we’re constantly learning, improving and maintaining the excellent uptime for which Coralogix is well known. The responsibility is now on us, to make sure this cannot happen again.
Appendices
Appendix 1: Impact to Coralogix data processing
The behavior can clearly be seen in the volume of data coming in we handled globally






The team is working to setup a pipeline to prevent dataloss and recover the services as soon as the AWS incident is resolved (Coralogix business continuity plan can be found here:https://coralogix.com/wp-content/uploads/2020/09/Business-Continuity-Plan.pdf).
Don't hesitate to contact our support for assistance.
AWS Status updates: https://health.aws.amazon.com/health/status